Nearly three-quarters of developers say they are responsible for managing the quality of the data they use in their applications, a key finding in the 2nd Data Quality Survey, completed in conjunction with data management provider Melissa in July.
In last year’s survey, the number of developers claiming this responsibility was less than 50%, supporting the notion that the role of software developers has expanded beyond writing code. As organizations move security, testing, governance and even marketing and finance earlier into the application life cycle, developers are squeezed for the time by ever-shrinking delivery timelines, and data quality often remains a “hope it’s right” afterthought to development teams.
Among the other key findings is that the top problem development teams face is the inconsistency of the data they need to utilize, followed closely by incomplete data and old/incorrect data. Last year’s top choice, duplicate data, fell to fourth this year. Misfielded data and international character set to round out the category.
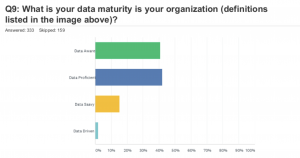
Because of these data problems, respondents to the survey said they spend about 10 hours per week dealing with data quality issues, taking time from building new applications. Despite these problems, some 83% of respondents claimed their organizations are either data proficient or data-aware, while only the remainder say they are data-savvy (15%) and data-driven (around 2%). According to the publisher:
“Data is critical to the success of organizations worldwide, and to find that such a small number consider themselves savvy or data-driven is somewhat alarming. With the world moving forward on data privacy and governance, to see organizations still failing to maintain their data should be a wake-up call for the industry at large.”
James Royster, the head of analytics at Adamas Pharmaceutical and formerly the senior director of analytics and data strategy for biopharmaceutical company Celgene said the big problem organizations face with their data is that there are “thousands of nuances” in big sets of data.
 Royster gave an example of IQVIA, a health care data connectivity solutions provider, which collects data from more than 60,000 pharmacies, each dispensing hundreds and thousands of drugs, serums and more. On top of that, they service hospitals and doctors’ offices. So, he explained, “there are millions of potential points of error.” And in order for companies to create these datasets, they have to have developers write code that brings these data sets together, in a way that can be digested by a company. And that’s an ongoing process. “So as they’re changing code, updating code, collecting data, whatever it is, there are millions of opportunities for things to go wrong.”
Royster gave an example of IQVIA, a health care data connectivity solutions provider, which collects data from more than 60,000 pharmacies, each dispensing hundreds and thousands of drugs, serums and more. On top of that, they service hospitals and doctors’ offices. So, he explained, “there are millions of potential points of error.” And in order for companies to create these datasets, they have to have developers write code that brings these data sets together, in a way that can be digested by a company. And that’s an ongoing process. “So as they’re changing code, updating code, collecting data, whatever it is, there are millions of opportunities for things to go wrong.”
But data issues don’t occur only in large organizations. Smaller companies also have problems with data, as they don’t have the resources to properly collect the data they need and monitor it for changes beyond someone in the database contacting them that something in their data has changed.
As an example, smaller companies might use a form to collect data for users, but many users provide bad data to avoid unwanted contact. The problem, Royster said, is that there’s nobody checking it or aggregating it or applying any sort of logic to it to say, this is how this should be. He concluded that it’s just data goes in, data comes out. And if that data that goes in is incorrect, what comes out is incorrect too.