
A research team from OpenAI proposes Codex, a specialized GPT model fine-tuned on publicly available code from GitHub that can produce functionally correct Python code bodies from natural language docstrings and could excel at a variety of coding tasks.
OpenAI’s GPT-3 has made headlines since its release last June. Recent integrations have revealed this large language model’s additional power and potential, such as the 2020 Brown et al. study showing its ability to generate simple programs from Python programming language docstrings.
Based on the considerable success of GPT-3 and the abundance of publicly available code in the GitHub repository, a research team from OpenAI has proposed Codex. This specialized GPT model is fine-tuned on GitHub code that produces functionally correct code bodies from natural language docstrings and could excel at a variety of coding tasks.
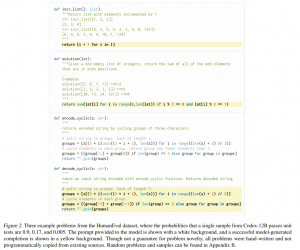
The novel study aims at generating standalone Python functions from docstrings and evaluating the correctness of code samples automatically through unit tests. The team first defines the pass@k metric, where k code samples are generated per problem, and a problem is considered solved if any sample passes the unit tests. The total fraction of problems solved is then reported. Next, they build a “HumanEval” handwritten problems dataset to assess language comprehension, reasoning, algorithms, and simple mathematics. Finally, they define the sandbox environment they used to safely execute model-generated code against unit tests. The researchers’ goal was to prevent these programs from modifying, gaining persistence on, accessing sensitive resources on, or exfiltrating data from a host or network.
The training datasets were collected from 54 million public software repositories hosted on GitHub, containing 179 GB of unique Python files under 1 MB. The team trained Codex using the GPT models with a 175 step linear warmup and cosine learning rate decay, basing their code lexer on the GPT-3 text tokenizer to maximally leverage GPT text representations. They fine-tuned Codex on the generated training problems to produce a set of “supervised fine-tuned” models, which they call Codex-S.
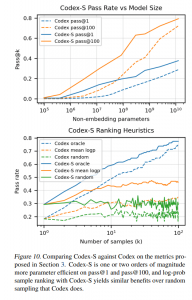
The team conducted a number of experiments to evaluate the performance of their fine-tuned Codex-S model. The team also plotted the performance of different sample-selection heuristics for Codex-S-12B against the same heuristics for Codex-12B, with Codex-S scoring over 2% higher than the Codex model. The study shows the proposed GPT-3 Codex models fine-tuned on GitHub code achieve strong performance on human-written problems with difficulty levels comparable to easy interview problems, demonstrating that GPT-3 can be trained to produce functionally correct code bodies from natural language docstrings.
The researchers note that model performance can be further improved by training on distributions similar to the evaluation set and by producing multiple samples from a model and that it is relatively simple to train a model to complete the reverse task of producing docstrings from code bodies.






