
Google has introduced Agentic Vision powered by Gemini 3 Flash, a new capability aimed squarely at software developers building real-time, vision-enabled applications. According to Google’s official developer blog, the update enables AI systems to move beyond static image understanding and into continuous perception, reasoning, and action—all with low latency and production-ready performance.
What “Agentic Vision” Means for Developers
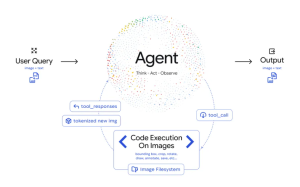
Traditional computer vision APIs are typically request–response: send an image, get labels or detections. Agentic Vision changes that model. With Gemini 3 Flash, developers can build visual agents that observe images or video streams, reason about what they see in the context of a goal, and decide what to do next—repeating this loop continuously.
In practice, this means AI systems that can watch, think, and act as part of an application workflow, rather than serving as a one-off inference step.
Why Gemini 3 Flash Is Optimized for Real-Time Use
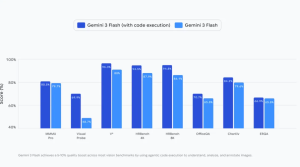
Gemini 3 Flash is designed for speed and efficiency, making it suitable for latency-sensitive scenarios where larger models may be too slow or costly. Google positions it as a strong default for:
- Real-time video analysis
- Interactive agents and assistants
- Automation pipelines that depend on visual feedback
For developers, this balance of multimodal reasoning + fast response times lowers the barrier to deploying vision-based AI in production systems.
From Vision Models to Visual Agents
Google emphasizes a shift in how developers should think about vision AI. Instead of asking “what’s in this image?”, agentic systems ask:
- What am I trying to achieve?
- What visual information is relevant right now?
- What action should I take next?
Using Gemini 3 Flash, developers can structure prompts and tool calls so the model actively plans its next step—whether that’s requesting another frame, calling an API, triggering an action, or asking a user for clarification.
Tool Use and Integration Patterns
Agentic Vision works especially well when combined with:
- Function calling to trigger application logic
- External tools and APIs for actions (alerts, database updates, device control)
- Structured prompts that define goals, constraints, and success criteria
This makes it easier to build end-to-end intelligent systems without heavy custom orchestration code. The model handles much of the reasoning flow, while developers retain control over execution.
Practical Use Cases for Software Teams
Google highlights several scenarios where Agentic Vision can immediately add value:
- Robotics and automation: systems that visually inspect environments and adapt behavior in real time
- Monitoring and inspection: detecting anomalies, changes, or safety issues from video feeds
- Interactive assistants: agents that understand visual context during conversations
- Developer tooling: AI that observes UI behavior, workflows, or system states visually
Across these use cases, the common theme is adaptability—AI that responds dynamically rather than following rigid rules.
A Broader Shift Toward Agentic Development
Agentic Vision with Gemini 3 Flash reflects a wider trend in software development: AI models are becoming participants in workflows, not just utilities. For developers, this means designing systems around goals and feedback loops, instead of static inputs and outputs.
Google’s approach focuses on making this shift practical—fast enough for real-time use, flexible enough for diverse applications, and accessible through familiar developer tooling.
For teams building the next generation of AI-powered software, Agentic Vision offers a clear signal of where things are heading: applications that see, reason, and act as part of the system itself.
Material by Iva Abadjievа
Source and image: Google Blog






